Additional resources
References
Pictue reference
Additional resources
References
Pictue reference
Session 1: Background
Session 2: Introduction to the math
Session 3: Exercises

Lewandowsky & Farrell. (2011). Computational modeling in cognition.
Choices between options
Judgments about “objects”
Biological measures


Miller & Page. (2007). Complex adaptive systems.

(LSE library, No known Copyright Restrictions)
a-posteriori (i.e., after data has been collected)
Principle of falsification
Corroboration
a-priori (i.e., before data is collected)
Empirical content:
Popper. (1982). Logik der Forschung.
Glöckner & Betsch. (2011). The empirical content of theories in judgment and decision making. JDM, 6, 711-721.
Jekel. (2019). Empirical content as a criterion for evaluating models. CP, 20, 273-275.
A model has a high level of universality if it applies to many situations.
Model A says something about situation 1 and 2, model B says only something about sitation 1. Model A has a higher level of universality.
Example
„If a child is frustrated, then it reacts aggressively.“
The degree of precision increases with the number of potential observations that falsify the model.
Example
Bröder. (2011). Versuchsplanung und experimentelles Praktikum

Roberts & Pashler. (2000). How persuasive is a good fit? […]. PR, 107, 358-367.

Gigerenzer & Brighton. (2009). Homo heuristicus […]. TiCS, 1, 107-143.
\[y = b_0 + b_1 \times x + b_2 \times x^2 + \ldots + b_z \times x^z + \epsilon \]
Determine the empirical content of the following five hypotheses
Model components: Properties of a situation (e.g., stimuli) and properties of a person (e.g. information processing style), etc. (everything that can be measured)
Behaviour: Choices, judgmens, etc. (everything that can be measured)
\[\text{model components(situation, person)} \rightarrow \text{model output(behaviour)}\]
Arrow = Mathematical function that describes how model input (options of a function) results into model output (output of a function)
Models that measure cognitive variables
(Process-)models that describe how information is processed

Krajbich & Rangel (2011). Multialternative drift-diffusion model […]. PNAS, 108, 13852-13857.

Farrell & Lewandowsky. (2010). Computational models as aids […]. CDiPS, 19, 329-335.





modified from Chambers, C. (2017). The seven deadly sins of psychology: […]. Princeton: University Press.

Chambers, C. (2017). The seven deadly sins of psychology: […]. Princeton: University Press.
Why do some people (exclusively) favor direct replications?
If the effect fails to replicate in a conceptual replication (i.e., \(p>.05\)):
As experimental psychologists we are trained to manipulate only one variable at a time to test causal relations.
BUT
Failure is still very informative on a theoretical level!
Simons, D. J. (2014). The value of direct replication. PPS, 9, 76-80.
Equivalence of conceptual replications to original studies should be determined on a theoretical level.
If the theory says “frustration leads to aggression”, the specific sample, the specific operationalizations of the constructs involved, etc. should not matter.
Thus, it is totally fine if the replication study differs from the original study:
Westfall et al. (2015). Replicating studies in which samples of participants respond to samples of stimuli. PPS, 10, 390-399.
Wells et al. (1999). Stimulus sampling and social psychological experimentation. PSPB, 25, 1115-1125.
Why are formalized process models better models?
Formalized models help us to run “thought experiments [that are] prosthetically regulated by computers” (Dennet, 1981, p. 117)


Decisions between options based on probabilistic cues with (un-)known validity.

Adaptive Toolbox Models
Gigerenzer, Todd, & The ABC Research Group, 1999
Parallel Constraint Satisfaction network model (Glöckner & Betsch, 2008)
Rumelhart & McClelland, 1986; Thagard, 1989, 2003; Read, Vanman, & Miller, 1997; Simon, 2004; Monroe & Read, 2008
| Cue | Stock A | Stock B | Validity |
|---|---|---|---|
| Expert A | 1 | -1 | 0.55 |
| Expert B | 1 | -1 | 0.54 |
| Expert C | -1 | 1 | 0.53 |
Definition validity:
\[val = \frac{freq_{\text{correct}}}{freq_{\text{correct}}+freq_{\text{incorrect}}}\]
| Cue | Stock A | Stock B | Validity |
|---|---|---|---|
| Expert A | 1 | -1 | 0.55 |
| Expert B | 1 | -1 | 0.54 |
| Expert C | -1 | 1 | 0.53 |
The most valid discriminating cue is used.
| Cue | Stock A | Stock B | Validity |
|---|---|---|---|
| Expert A | 1 | -1 | 0.55 |
| Expert B | 1 | -1 | 0.54 |
| Expert C | -1 | 1 | 0.53 |
| Sum | 1 | -1 |
The unweighted sum of cues is used.
| Cue | Stock A | Stock B | Validity |
|---|---|---|---|
| Expert A | 1 | -1 | 0.55 |
| Expert B | 1 | -1 | 0.54 |
| Expert C | -1 | 1 | 0.53 |
| Weighted Sum | 0.56 | -0.56 |
The weighted sum of cues is used.




\[w = (val - .5)^P\]





Introduction to equations:
http://coherence-based-reasoning-and-rationality.de/slides_PCS.html#/
Online-GUI:
https://coherence.shinyapps.io/PCSDM/

Modeling choices
Modeling other process measures
Density Function of the normal distribution
Comparing models
Nested models
Likelihood Ratio Test
Unnested models
What is the probability of the following sequence of events: Heads, H, Tails, T, T, T, T, H, H, H

What is the probability of the following sequence of events: Heads, H, Tails, T, T, T, T, H, H, H
\[p(H|\text{fair}) = p(H|\text{fair}) = .5\]
\[p(H, H, T, T, T, T, T, H, H, H|.5) = .5^6 \times (1-.5)^4 = .5^{10}\]
What is the probability of 6 heads and 4 tails (i.e., N = 10 draws):
Binomial distribution
Example
What is the probability to observe 9 or 10 heads in 10 tosses if the probability of head is .65?
What is the likelihood for 6 heads and 4 tails for a specific \(\theta\) given the data?
\[L(\theta|6H,4T) = p(6H,4T|\theta) = \binom{10}{6} \times \theta^6 \times (1-\theta)^4\]

Which \(\theta\) results in the maximum likelihood given the data?
\[L(\theta|6H,4T) = p(6H,4T|\theta) = \binom{10}{6} \times \theta^6 \times (1-\theta)^4\]


What is the most plausible parameter for the probability of heads if we observe 9 heads in 10 tosses?

Heads = Model-consistent choices
Tails = Model-inconsistent choices

Moshagen & Hilbig, 2011; Bröder & Schiffer, 2003
\[L_{Choices}= p(n_{jk}|k,\epsilon_k) = \prod^J_{j=1}\begin{pmatrix} n_j\\n_{jk}\end{pmatrix}(1-\epsilon_k)^{n_{jk}}\epsilon_k^{(n_j-n_{jk})}\]
\(n_{j}\) = Number of repetitions task type \(j\)
\(n_{jk}\) = Number of choices per task type \(j\) consistent with model \(k\)
\(\theta = 1 - \epsilon_k\) mit \(\epsilon_k\) = application error model \(k\)
Density function of a normal distribution
\[p(d|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \times e^{-(\text{d} -\mu)^2/(2\sigma^2)}\]
Example \(\mu = 0\), \(\sigma = 2\)

\[L(\mu,\sigma^2|d) = \frac{1}{\sqrt{2\pi\sigma^2}} \times e^{-(\text{d} -\mu)^2/(2\sigma^2)}\]
Free (= unknown) parameters: \(\mu\), \(\sigma\)
\(d = 3\), \(\sigma = 2\)

\(d = 3\), \(\mu = 1\)

Total Likelihood
\[L(\theta|D) = L(\theta|d_1) \times L(\theta|d_2) \times \ldots \times L(\theta|d_n) \]
Total Log-Likelihood
\[log[L(\theta|D)] = log[L(\theta|d_1) \times L(\theta|d_2) \times \ldots \times L(\theta|d_n)] =\] \[= log[L(\theta|d_1)] + log[L(\theta|d_2)] + \ldots + log[L(\theta|d_n)] \]
\[ y = N(\mu,\sigma)\]
\[ y = \beta_0 + N(0,\sigma)\]
\[ y = \beta_0^* + \beta_1 \times S + N(0,\sigma)\]

\[error = N(0,\sigma)\]


Simplex (Nelder-Mead)

Lewandowsky & Farrell (2011, S. 83)
(Log-)Likelihood Ratio-Test
\[\chi^2 \approx -2 \times ln\left(\frac{L_{\text{simple}}}{L_{\text{general}}}\right)\]
The resulting test statistic is \(\chi^2\)-distributed with \(df =\) difference in the number of parameters.
Example
Model 1:
\[y = b_0 + b_1 \times x_1 + b_2\times x_2 \]
Model 2:
\[y = b_0^* + b_1^* \times x_1 \]
Model 2 is nested in model 1.
We need to talk about Bayes.

\(\Large p(A) = \frac{freq(A)}{freq(U)}\)

\(\Large p(B) = \frac{freq(B)}{freq(U)}\)

\(\Large p(A \cap B) = \frac{freq(A \cap B)}{freq(U)}\)

\(\Large p(A|B) = \frac{freq(A \cap B)}{freq(B)}\)
\(\Large p(A|B) = \frac{freq(A \cap B)/freq(U)}{freq(B)/freq(U)}\)
\(\Large p(A|B) = \frac{p(A\cap B)}{p(B)}\)
B happened
Equation 1
\(\Large p(A|B) = \frac{p(A \cap B)}{p(B)}\)
A happened
Equation 2
\(\Large p(B|A) = \frac{p(A \cap B)}{p(A)}\)
B happened
Equation 1
\(\Large p(A|B) = \frac{p(A \cap B)}{p(B)}\)
A happened
Equation 2
\(\Large p(B|A) = \frac{p(A \cap B)}{p(A)}\)
Equation 2
\(\Large p(A \cap B) = p(B|A) \times p(A)\)
Equation 1
\(\Large p(A|B) = \frac{p(A \cap B)}{p(B)}\)
Equation 2
\(\Large p(A \cap B) = p(B|A) \times p(A)\)
Put equation 2 in equation 1
\(\Large p(A|B) = \frac{ p(B|A) \times p(A)}{p(B)}\)
\(\Large p(A|B) = \frac{p(A)}{p(B)} \times p(B|A)\)
A: Sickness+, B: Test+
\(\Large p(\text{Sickness+}|\text{Test+}) = \frac{p(\text{Sickness+})}{p(\text{Test+})} \times p(\text{Test+}|\text{Sickness+})\)
A: \(model\), B: data \(d\)
\(\Large p(model|d) = \frac{p(model)}{p(d)} \times p(d|model) = p(model) \times \frac{p(d|model)}{p(d)}\)
\[p(model_A|d) = p(model_A) \times \frac{p(d|model_A)}{p(d)}\]
\[p(model_B|d) = p(model_B) \times \frac{p(d|model_B)}{p(d)}\]
Posterior Odds:
\[ \frac{p(model_A|d)}{p(model_B|d)} = \frac{p(model_A)}{p(model_B)} \times \frac{p(d|model_A)}{p(d|model_B)}\]
\[\text{Posterior Odds} = \text{Prior Odds} \times \text{Bayes Factor}\]
Bayes-Factor:
\[\frac{p(d|model_A)}{p(d|model_B)} = \frac{\int p(d|\theta_A,model_A)\times p(\theta_A,model_A)d\theta_A}{\int p(d|\theta_B,model_B)\times p(\theta_B,model_B)d\theta_B}\]
Approximation:
\[-2 \times log(p(d|model_A)) \approx BIC_A = -2 \times log(L(\hat{\theta_A}|d,model_A)) + K \times log(N)\]
\(K\) = Number of free parameters; \(N\) = Number of data points
Bayes-Factor:
\[BF = \frac{p(d|model_A)}{p(d|model_B)} = e^{( -\frac{1}{2} \times \Delta BIC)}\]Schwarz, 1978
\(BF_{AB}\):
Wagenmakers et al., 2011; Jeffreys, 1961
Functional flexibility and model fit
\(y = x^b\) versus \(y = b \times x\)
Relative versus absolute fit



\[NML = \frac{L(\hat{\theta}|d)}{\sum_{x \in X}L(\hat{\theta}|x)}\]
\(\theta\) model parameters
\(d\) data
\(L(\hat{\theta}|d)\) Maximum Likelihood
\(X\) all possible data
Davis-Stober & Brown, 2011
Moshagen & Hilbig, 2011; Bröder & Schiffer, 2003

Moshagen & Hilbig, 2011
What is a good benchmark model?
A model that is maximally flexible: The model allows for each item type an individual \(\epsilon\).
(i.e., if a participant chose 8 times option A and 2 times option B, the model “predicts” \(1-\epsilon = .8\) for option A, if a participant chose 3 times option A and 7 times option B, the model “predicts” \(1-\epsilon = .7\) for option B, etc.)
How do we test that the real model does not fit the data worse than the benchmark model?
Different implementation for error probabilities \(\epsilon\)
Distribution of posterior probabilities for errors \(\epsilon\)
Lee, M. (2015). Bayesian outcome-based strategy classification. Behavior Research Methods.


Situation:
Methodological challenge
Jekel et al. (2010). Implementation of the multiple-measure maximum likelihood strategy classification method in R […]. JDM, 5, 54–63.
Given
Required
Goal
Assess the fit between data and models
| A B | A B | A B | A B | A B | A B | |
|---|---|---|---|---|---|---|
| Cue 1 (v = .80) | \(-\) \(+\) | \(-\) \(+\) | \(-\) \(+\) | \(+\) \(+\) | \(-\) \(+\) | \(+\) \(-\) |
| Cue 2 (v = .70) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(+\) | \(+\) \(-\) |
| Cue 3 (v = .60) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(+\) | \(+\) \(-\) | \(+\) \(-\) |
| Cue 4 (v = .55) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) |
| Choice | B | B | B | A | B | A |
| Time | 4 | 4 | 4 | 13 | 4 | 4 |
| Confidence | 0.8 | 0.8 | 0.8 | 0.55 | 0.8 | 0.8 |
| A B | A B | A B | A B | A B | A B | |
|---|---|---|---|---|---|---|
| Cue 1 (v = .80) | \(-\) \(+\) | \(-\) \(+\) | \(-\) \(+\) | \(+\) \(+\) | \(-\) \(+\) | \(+\) \(-\) |
| Cue 2 (v = .70) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(+\) | \(+\) \(-\) |
| Cue 3 (v = .60) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(+\) | \(+\) \(-\) | \(+\) \(-\) |
| Cue 4 (v = .55) | \(+\) \(-\) | \(+\) \(+\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(-\) | \(+\) \(+\) |
| Choices | B | B | B | A | B | A |
| Time | -0.167 | -0.167 | -0.167 | 0.833 | -0.167 | -0.167 |
| Confidence | 0.167 | 0.167 | 0.167 | -0.833 | 0.8 | 0.167 |
\[R^C = (R - \overline{R})/(max(R)-min(R))\]
| Dependent Measures | Distribution |
|---|---|
| Choices | Binomial |
| Residuals of log(Decision Time) | Normal |
| Residuals of Confidence-ratings | Normal |
Likelihood-Function
\[ L_{Time}= p(\vec{x}_T|k,R_T,\mu_T,\sigma_T) = \prod^I_{i=1}\frac{1}{\sqrt{2\pi\sigma_T^2}}e^{-\frac{(x_{T_i}-\mu^*)^2}{2\sigma_T^2}}\]
Contrast
\[ \mu^* = \mu_T+t_{T_i}R_T \]
Regression Notation
\[log(R_T) = b_{\mu_T} + b_{R_T} \times x_{t_{T_i}} + e\]
\[e \sim N(0,sd)\]

\[ \mu^* = \mu_T+ t_{T_i} \times R_T \text{, with } t_{T_i} = \{0,0,.0\} \]
\[\mu^* = \mu_T \] 
\[
\mu^* = \mu_T
\] 
\[ \mu^* = \mu_T \]
\[
\mu^* = \mu_T+ t_{T_i} \times R_T \text{, with } t_{T_i} = \{-.5,0,.5\}
\] 
\[
\mu^* = \mu_T+ t_{T_i} \times R_T \text{, with } t_{T_i} = \{-.5,0,.5\}
\] 
\[ \mu^* = \mu_T+ t_{T_i} \times R_T \text{, with } t_{T_i} = \{-.5,0,.5\} \]
\[ \mu^* = \mu_T+ t_{T_i} \times R_T \text{, with } t_{T_i} = \{-.5,0,.5\} \]
Total Likelihood:
\[L_{total}= L_{Choices} \times L_{Time} \times L_{Confidence}\]
Choices, Decision Time, and Confidence Ratings
\[L_{total}= p(n_{jk},\vec{x}_T,\vec{x}_C|k,\epsilon_k,\mu_T,\sigma_T,R_T,\mu_C,\sigma_C,R_C)=\]
\[=\prod^J_{j=1} \binom{n_j} {n_{jk}}(1-\epsilon_k)^{n_{jk}}\epsilon_k^{(n_j-n_{jk})} \times\]
\[\times \prod^I_{i=1}\frac{1}{\sqrt{2\pi\sigma_T^2}}e^{-\frac{(x_{T_i}-(\mu_T+t_{T_i}R_T))^2}{2\sigma_T^2}}\times\]
\[\times \prod^I_{i=1}\frac{1}{\sqrt{2\pi\sigma_C^2}}e^{-\frac{(x_{C_i}-(\mu_C+t_{C_i}R_C))^2}{2\sigma_C^2}}\]
Situation:
Methodological challenge

Jekel et al. (2011). Diagnostic task selection for strategy classification in judgment and decision making […], JDM, 6, 782–799.



\[D^k_{m_{ij}} = \sqrt{(ch_{m_i} - ch_{m_j})^2 + (dt_{m_i} - dt_{m_j})^2 + (co_{m_i} - co_{m_j})^2}\]
| Model 1 versus 2 | Model 1 versus 3 | Model 2 versus 3 | |
|---|---|---|---|
| Task 1 | D_T1_M12 | D_T1_M13 | D_T1_M23 |
| Task 2 | D_T2_M12 | D_T2_M13 | D_T2_M23 |
| … | … | … | … |
| Task n | D_Tn_M12 | D_Tn_M13 | D_Tn_M23 |
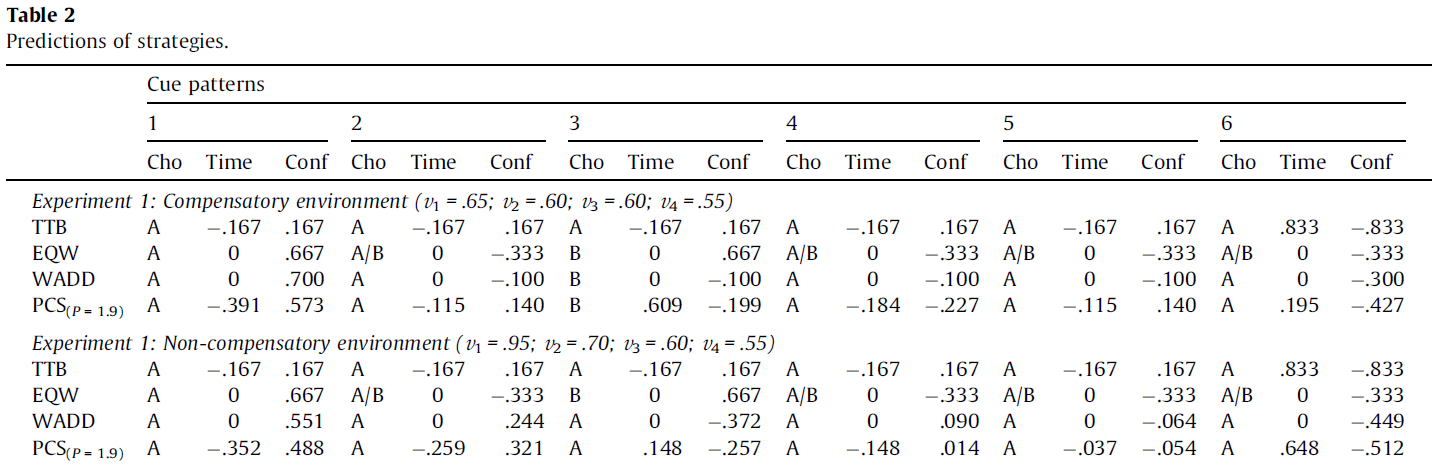
40 tasks and 5 models (black = PCS, blue = TTB, red = EQW, green = WADD, purple = Random)

We simulated behaviour of participants that apply a specific strategy with a specific application error for different tasks in different environments.
We used EDTS to identify tasks and MM-ML to classifiy participants.

Diagnostic tasks for models with free oarameters
Pfeiffer, J., Duzevik, D., Rothlauf, F., Bonabeau, E., & Yamamoto, K. (2014). An optimized design of choice experiments: A new approach for studying decision behavior in choice task experiments. Journal of Behavioral Decision Making.
Diagnosticity based on a Bayesian analysis
Cavagnaro, D. R., Pitt, M. A., & Myung, J. I. (2011). Model discrimination through adaptive experimentation. Psychonomic Bulletin & Review, 18, 204–210.
How can I do all this in practice without the need of programming?
EDTS
## function (setWorkingDirectory = "c:/EDTS_v2.0/", validities = c(0.8,
## 0.7, 0.6, 0.55), measures = c("choice", "time", "confidence"),
## rescaleMeasures = c(0, 1, 1), weightingMeasures = c(1, 1,
## 1), strategies = c("PCS", "TTB", "EQW", "WADDcorr", "RAND",
## "RAT", "WADDuncorr"), generateTasks = 1, reduceSetOfTasks = 1,
## derivePredictions = 1, printStatus = 1, saveFiles = 1, setOfTasks = "none",
## distanceMetric = "Euclidian", loadFunctions = 1, PCSdecay = 0.05,
## PCSfloor = -1, PCSceiling = 1, PCSstability = 10^6, PCSsubtrahendResc = 0.5,
## PCSfactorResc = 1, PCSexponentResc = 2)
## {
## setwd(setWorkingDirectory)
## numbOfCues = length(validities)
## if (generateTasks == 1 & length(setOfTasks) == 1) {
## if (printStatus == 1) {
## print("####################################################")
## print("############## generating/loading environment ######")
## print("####################################################")
## }
## source("taskGenerator.r")
## patternQualified = taskGenerator(reduceSetOfTasks, numbOfCues,
## saveFiles = saveFiles)
## }
## else {
## if (length(setOfTasks) == 1) {
## patternQualified = as.matrix(read.csv("tasks.csv"))
## }
## else {
## patternQualified = setOfTasks
## }
## }
## if (printStatus == 1) {
## print("done")
## }
## if (printStatus == 1) {
## print("####################################################")
## print("############## deriving/loading predictions ########")
## print("####################################################")
## }
## numbOfCuePatterns = max(patternQualified[, 1])
## if (loadFunctions == 1) {
## source("strategies/PCSv2.r")
## source("strategies/transformStandardPCS.r")
## source("strategies/TTB.r")
## source("strategies/EQW.r")
## source("strategies/WADDcorr.r")
## source("strategies/RAT.r")
## source("strategies/WADDuncorr.r")
## }
## PCSPred = matrix(NA, numbOfCuePatterns, 3)
## TTBPred = matrix(NA, numbOfCuePatterns, 3)
## EQWPred = matrix(NA, numbOfCuePatterns, 3)
## WADDcorrPred = matrix(NA, numbOfCuePatterns, 3)
## RandomPred = matrix(NA, numbOfCuePatterns, 3)
## RATPred = matrix(NA, numbOfCuePatterns, 3)
## WADDuncorrPred = matrix(NA, numbOfCuePatterns, 3)
## if (derivePredictions == 1) {
## for (itemLoop in 1:numbOfCuePatterns) {
## if ("PCS" %in% strategies == TRUE) {
## matrixPCS = transPCSpairwiseComp((PCSfactorResc *
## (validities - PCSsubtrahendResc))^PCSexponentResc,
## 0.01 * patternQualified[patternQualified[,
## 1] == itemLoop, 2:3], numbCues = numbOfCues)
## PCSout = PCSv2(activ = c(1, rep(0, numbOfCues),
## 0, 0), weightsNet = matrixPCS, decay = PCSdecay,
## flo = PCSfloor, ceil = PCSceiling, stability = PCSstability)
## PCSresul = ifelse(round(PCSout[length(PCSout)],
## 6) > round(PCSout[length(PCSout) - 1], 6),
## 0, 1)
## PCSresul = ifelse(round(PCSout[length(PCSout)],
## 6) == round(PCSout[length(PCSout) - 1], 6),
## 0.5, PCSresul)
## PCSresul = c(PCSresul, PCSout[1], abs(PCSout[length(PCSout) -
## 1] - PCSout[length(PCSout)]))
## PCSPred[itemLoop, ] = PCSresul
## }
## if ("TTB" %in% strategies == TRUE) {
## TTBPred[itemLoop, ] = TTB(validities = validities,
## cuePattern = patternQualified[patternQualified[,
## 1] == itemLoop, 2:3])
## }
## if ("EQW" %in% strategies == TRUE) {
## EQWPred[itemLoop, ] = EQW(validities = validities,
## cuePattern = patternQualified[patternQualified[,
## 1] == itemLoop, 2:3])
## }
## if ("WADDcorr" %in% strategies == TRUE) {
## WADDcorrPred[itemLoop, ] = WADDcorr(validities = validities,
## cuePattern = patternQualified[patternQualified[,
## 1] == itemLoop, 2:3])
## }
## if ("RAND" %in% strategies == TRUE) {
## RandomPred[itemLoop, ] = c(1/2, 0, 0)
## }
## if ("RAT" %in% strategies == TRUE) {
## RATPred[itemLoop, ] = RAT(validities = validities,
## cuePattern = patternQualified[patternQualified[,
## 1] == itemLoop, 2:3])
## }
## if ("WADDuncorr" %in% strategies == TRUE) {
## WADDuncorrPred[itemLoop, ] = WADDuncorr(validities = validities,
## cuePattern = patternQualified[patternQualified[,
## 1] == itemLoop, 2:3])
## }
## if (printStatus == 1) {
## print(paste("predictions for task #", itemLoop,
## "of", numbOfCuePatterns, "derived"))
## }
## }
## totalPredictions = cbind(1:numbOfCuePatterns, PCSPred,
## TTBPred, EQWPred, WADDcorrPred, RandomPred, RATPred,
## WADDuncorrPred)
## colnames(totalPredictions) = c("Task.Number", paste(rep(c("PCS.",
## "TTB.", "EQW.", "WADDcorr.", "RAND.", "RAT.", "WADDuncorr."),
## each = 3), c("choice", "time", "confidence"), sep = ""))
## }
## else {
## totalPredictions = as.matrix(read.csv("predictions.csv"))
## }
## totalPredictions = totalPredictions[, is.na(colSums(totalPredictions)) ==
## FALSE]
## namesPred = colnames(totalPredictions)
## indexStratCheck = c(2, 2, rep(c(1, 0), (length(namesPred) -
## 1)))
## namesStrategies = (unlist(strsplit(namesPred, ".", fixed = T))[indexStratCheck ==
## 1])
## namesMeasures = (unlist(strsplit(namesPred, ".", fixed = T))[indexStratCheck ==
## 0])
## numbOfCuePatterns = NROW(totalPredictions)
## strategiesIncludedForEDTS = namesStrategies %in% strategies
## measuresIncludedForEDTS = namesMeasures %in% measures
## namesStrategiesIncludedForEDTS = unique(namesStrategies[strategiesIncludedForEDTS])
## namesMeasuresIncludedForEDTS = unique(namesMeasures[measuresIncludedForEDTS])
## numberOfMeasures = length(namesMeasuresIncludedForEDTS)
## numberOfStrategies = length(namesStrategiesIncludedForEDTS)
## include = colSums(rbind(strategiesIncludedForEDTS, measuresIncludedForEDTS)) ==
## 2
## if (length(weightingMeasures) != numberOfMeasures) {
## weightingMeasures = rep(1, numberOfMeasures)
## }
## totalPredictions = totalPredictions[, c(TRUE, include)]
## if (saveFiles == 1 & derivePredictions == 1) {
## write.csv(totalPredictions, "predictions.csv", row.names = F)
## }
## if (printStatus == 1) {
## print("done")
## print("####################################################")
## print("############## applying EDTS #######################")
## print("####################################################")
## print("#")
## }
## predictionsRescaled = t((t(totalPredictions) - apply(totalPredictions,
## 2, min))/(apply(totalPredictions, 2, max) - apply(totalPredictions,
## 2, min)))
## if (numberOfMeasures != length(rescaleMeasures)) {
## rescaleMeasures = rep(1, numberOfMeasures)
## }
## rescaleMeasuresIndex = c(999, rep(rescaleMeasures, numberOfStrategies))
## predictionsRescaled[, rescaleMeasuresIndex == 0] = totalPredictions[,
## rescaleMeasuresIndex == 0]
## predictionsRescaled = ifelse(is.na(predictionsRescaled),
## 0, predictionsRescaled)
## predictionsRescaled[, 1] = 1:numbOfCuePatterns
## if (printStatus == 1) {
## print("############################################")
## print("############### set of strategies ##########")
## print("############################################")
## print(namesStrategiesIncludedForEDTS)
## print("############################################")
## print("############### number of tasks ############")
## print("############################################")
## print(NROW(totalPredictions))
## print("############################################")
## print("############### set of measures ############")
## print("############################################")
## print(namesMeasuresIncludedForEDTS)
## print("############################################")
## print("############### rescaled measures ##########")
## print("############################################")
## if (length(namesMeasuresIncludedForEDTS[rescaleMeasures ==
## 1]) > 0) {
## print(namesMeasuresIncludedForEDTS[rescaleMeasures ==
## 1])
## }
## else {
## print("none")
## }
## print("############################################")
## print("############### weighting measures #########")
## print("############################################")
## print(paste(namesMeasuresIncludedForEDTS, ": ", weightingMeasures,
## sep = ""))
## }
## stratComparisons = combn(1:numberOfStrategies, 2)
## ED = matrix(NA, numbOfCuePatterns, NCOL(stratComparisons))
## stratCoding = rep(1:numberOfStrategies, each = numberOfMeasures)
## stratCoding = c(max(stratCoding) + 1, stratCoding)
## for (loopEDTS in 1:NCOL(stratComparisons)) {
## if (distanceMetric == "Euclidian") {
## ED[, loopEDTS] = sqrt(rowSums(cbind((t(weightingMeasures *
## t(predictionsRescaled[, stratCoding == stratComparisons[1,
## loopEDTS]] - predictionsRescaled[, stratCoding ==
## stratComparisons[2, loopEDTS]])))^2, 0)))
## }
## if (distanceMetric == "Taxicab") {
## ED[, loopEDTS] = rowSums(cbind(abs(t(weightingMeasures *
## t(predictionsRescaled[, stratCoding == stratComparisons[1,
## loopEDTS]] - predictionsRescaled[, stratCoding ==
## stratComparisons[2, loopEDTS]]))), 0))
## }
## }
## EDRescaled = t((t(ED) - apply(ED, 2, min))/(apply(ED, 2,
## max) - apply(ED, 2, min)))
## EDRescaled = ifelse(is.na(EDRescaled) == TRUE, ED, EDRescaled)
## ADMean = apply(EDRescaled, 1, mean)
## ADMin = apply(EDRescaled, 1, min)
## ADMax = apply(EDRescaled, 1, max)
## ADMedian = apply(EDRescaled, 1, median)
## ADcomplete = cbind(1:numbOfCuePatterns, ADMean, ADMin, ADMax,
## ADMedian, EDRescaled)
## namesComparisons = paste("Diag", namesStrategiesIncludedForEDTS[stratComparisons[1,
## ]], namesStrategiesIncludedForEDTS[stratComparisons[2,
## ]], sep = ".")
## colnames(ADcomplete) = c("Task.Number", "AD", "Diag.Min",
## "Diag.Max", "Diag.Median", namesComparisons)
## if (saveFiles == 1) {
## write.csv(ADcomplete, "outputEDTS.csv", row.names = F)
## }
## if (printStatus == 1) {
## print("####################################################")
## print("##################### done #########################")
## print("####################################################")
## }
## return(list(tasks = patternQualified, validities = validities,
## predictions = totalPredictions, EDTS = ADcomplete))
## }



Non-Compensatory environment: \(val = \{0.95,0.70,0.60,0.55\}\),
Compensatory environment: \(val = \{0.65,0.60,0.60,0.55\}\)
130,135,157,140,146,184
Link to article, Link to data compensatory, Link to data noncompensatory
source("DemoCognition.r",echo=T,max.deparse.length=10^100000)
##
## > print("##########################################")
## [1] "##########################################"
##
## > print("read in data")
## [1] "read in data"
##
## > dats = read.csv("exp1_w_pred.csv")
##
## > print("##########################################")
## [1] "##########################################"
##
## > dim(dats)
## [1] 5160 55
##
## > head(dats)
## subj v1 v2 v3 v4 o1c1 o1c2 o1c3 o1c4 o2c1 o2c2 o2c3 o2c4 choice
## 1 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## 2 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## 3 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## 4 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## 5 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## 6 4 0.95 0.7 0.6 0.55 1 1 1 -1 -1 -1 -1 1 1
## time conf order gamble_order cue1_order cue2_order cue3_order cue4_order
## 1 2779 17 29 2 1 4 2 3
## 2 3729 40 21 1 3 4 2 1
## 3 2249 61 47 1 2 3 1 4
## 4 4694 51 17 2 2 4 1 3
## 5 2873 54 32 1 3 4 2 1
## 6 3799 45 25 2 2 4 3 1
## age female cond choice1 n dec_numb pattern ln_time time_pred
## 1 20 1 2 1 1 1 1 7.929846 -0.6590635
## 2 20 1 2 1 2 2 1 8.223895 -0.4582239
## 3 20 1 2 1 3 3 1 7.718241 -0.6609485
## 4 20 1 2 1 4 4 1 8.454040 -0.2746830
## 5 20 1 2 1 5 5 1 7.963112 -0.5908445
## 6 20 1 2 1 6 6 1 8.242494 -0.3930207
## TTB_choice TTB_time TTB_conf EQW_choice EQW_time EQW_conf WADD_choice
## 1 1 1 0.95 1 1 4 1
## 2 1 1 0.95 1 1 4 1
## 3 1 1 0.95 1 1 4 1
## 4 1 1 0.95 1 1 4 1
## 5 1 1 0.95 1 1 4 1
## 6 1 1 0.95 1 1 4 1
## WADD_time WADD_conf r_o1c1 r_o2c1 r_v1 r_o1c2 r_o2c2 r_v2
## 1 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## 2 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## 3 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## 4 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## 5 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## 6 1 1.4 0.01 -0.01 0.2193329 0.01 -0.01 0.04698476
## r_o1c3 r_o2c3 r_v3 r_o1c4 r_o2c4 r_v4 PCS_choice PCS_time
## 1 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## 2 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## 3 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## 4 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## 5 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## 6 0.01 -0.01 0.01258925 -0.01 0.01 0.003373207 1 130
## PCS_conf
## 1 1.107068
## 2 1.107068
## 3 1.107068
## 4 1.107068
## 5 1.107068
## 6 1.107068
##
## > print("condition compensatory or noncompensatory")
## [1] "condition compensatory or noncompensatory"
##
## > condComp = ifelse(dats[, 2] == 0.65, 1, 0)
##
## > print("##########################################")
## [1] "##########################################"
##
## > print("subset data")
## [1] "subset data"
##
## > subsetdats = cbind(dats[, c("subj", "choice", "ln_time",
## + "conf", "cond", "TTB_choice", "TTB_time", "TTB_conf", "PCS_choice",
## + "PCS_time", "PCS_conf")])
##
## > print("##########################################")
## [1] "##########################################"
##
## > print("number of trials per participant")
## [1] "number of trials per participant"
##
## > table(subsetdats[, 1])
##
## 3 4 6 7 9 12 14 16 17 19 20 21 23 24 25 26 27 30
## 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60
## 31 32 33 37 41 42 43 44 45 47 48 49 51 52 53 55 56 57
## 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60
## 58 59 61 62 64 65 66 67 68 69 70 72 73 74 75 76 78 81
## 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60
## 83 84 85 91 92 93 94 95 96 97 98 99 100 102 103 104 109 120
## 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60 60
## 121 122 123 124 125 127 128 129 130 131 132 133 135 136
## 60 60 60 60 60 60 60 60 60 60 60 60 60 60
##
## > print("##########################################")
## [1] "##########################################"
##
## > print("mmmml format")
## [1] "mmmml format"
##
## > mmmlData = subsetdats[, c("subj", "choice", "ln_time",
## + "conf")]
##
## > mmmlData = cbind(mmmlData[, 1], 1:60, rep(1:6, each = 10),
## + mmmlData[, 2:4])
##
## > mmmlData[, 4] = ifelse(mmmlData[, 4] == 2, 0, 1)
##
## > mmmlData[, 1] = rep(1:length(table(subsetdats[, 1])),
## + each = table(subsetdats[, 1])[1])
##
## > colnames(mmmlData) = c("PARTICIPANT", "DEC", "TYPE",
## + "ACHOICES", "DECTIMES", "CONFJUDGMENTS")
##
## > mmmlData_comp = mmmlData[condComp == 1, ]
##
## > mmmlData_noncomp = mmmlData[condComp == 0, ]
##
## > mmmlData_comp[, 1] = rep(1:length(table(mmmlData_comp[,
## + 1])), each = table(mmmlData_comp[, 1])[1])
##
## > mmmlData_noncomp[, 1] = rep(1:length(table(mmmlData_noncomp[,
## + 1])), each = table(mmmlData_noncomp[, 1])[1])
##
## > write.csv(mmmlData_comp, file = "mmmlData_comp.csv",
## + row.names = F)
##
## > write.csv(mmmlData_noncomp, file = "mmmlData_noncomp.csv",
## + row.names = F)
MMML
## function (partic = 1:max(dat$PARTICIPANT), stratname = "NONAME",
## expectedchoice = "none", contrasttime = "none", contrastconfidence = "none",
## saveoutput = 1, directoryData = "datafunction.csv", directoryOutput = "output.csv",
## separator = ",", numberOFiterations = 10^9, relconvergencefactor = 10^-15)
## {
## library(stats4)
## controlParameterMLE = list(maxit = numberOFiterations, reltol = relconvergencefactor)
## dat = read.csv(directoryData, sep = separator, header = T)
## guessing = 0
## zerocontrasttime = 0
## zerocontrastconfidence = 0
## counterGUESSING = 0
## memory = numeric()
## choice = numeric()
## if (expectedchoice[1] != "none") {
## for (i in 1:length(expectedchoice)) {
## if (expectedchoice[i] == 1/2) {
## counterGUESSING = counterGUESSING + 1
## }
## }
## if (counterGUESSING == length(expectedchoice)) {
## guessing = 1
## }
## }
## if (contrasttime[1] != "none") {
## if (sum(abs(contrasttime)) == 0 | sd(contrasttime) ==
## 0) {
## zerocontrasttime = 1
## contrasttime = rep(0, length(contrasttime))
## }
## }
## if (contrastconfidence[1] != "none") {
## if (sum(abs(contrastconfidence)) == 0 | sd(contrastconfidence) ==
## 0) {
## zerocontrastconfidence = 1
## contrastconfidence = rep(0, length(contrastconfidence))
## }
## }
## numberOFfreeParameters = 7
## if (guessing == 1) {
## numberOFfreeParameters = numberOFfreeParameters - 1
## }
## if (expectedchoice[1] == "none") {
## numberOFfreeParameters = numberOFfreeParameters - 1
## }
## if (contrasttime[1] == "none") {
## numberOFfreeParameters = numberOFfreeParameters - 3
## }
## if (contrastconfidence[1] == "none") {
## numberOFfreeParameters = numberOFfreeParameters - 3
## }
## if (zerocontrasttime == 1) {
## numberOFfreeParameters = numberOFfreeParameters - 1
## }
## if (zerocontrastconfidence == 1) {
## numberOFfreeParameters = numberOFfreeParameters - 1
## }
## if (contrasttime[1] != "none" & zerocontrasttime != 1) {
## contrasttime = contrasttime - (sum(contrasttime)/length(contrasttime))
## rangetime = range(contrasttime)[2] - range(contrasttime)[1]
## contrasttime = contrasttime/rangetime
## }
## if (contrastconfidence[1] != "none" & zerocontrastconfidence !=
## 1) {
## contrastconfidence = contrastconfidence - (sum(contrastconfidence)/length(contrastconfidence))
## rangeconfidence = range(contrastconfidence)[2] - range(contrastconfidence)[1]
## contrastconfidence = contrastconfidence/rangeconfidence
## }
## for (numbpartic in 1:length(partic)) {
## numberOFtypes = max(dat$TYPE[dat$PARTICIPANT == partic[numbpartic]])
## numberOFtasksPerType = numeric()
## for (loopnumberOFtasksPerType in 1:numberOFtypes) {
## numberOFtasksPerType[loopnumberOFtasksPerType] = NROW(dat[dat$TYPE ==
## loopnumberOFtasksPerType & dat$PARTICIPANT ==
## partic[numbpartic], ])
## }
## logliks = c(0, 0, 0)
## numberOFmeasures = 0
## stratOutput = numeric()
## epsilon = numeric()
## messageerror = ""
## if (expectedchoice[1] != "none") {
## for (looptype in 1:numberOFtypes) {
## choice[looptype] = sum(dat$ACHOICES[dat$PARTICIPANT ==
## partic[numbpartic] & dat$TYPE == looptype])
## }
## OnEpsilon = ifelse(expectedchoice == 1/2, 0, 1)
## FixedEpsilon = ifelse(expectedchoice == 1/2, 1/2,
## 0)
## checkProp = ifelse(choice == expectedchoice, 1, 0)
## checkProp = ifelse(choice == (numberOFtasksPerType -
## expectedchoice), 2, checkProp)
## if ((sum(checkProp[expectedchoice != 0.5] == 1) ==
## sum(expectedchoice != 0.5)) | (sum(checkProp[expectedchoice !=
## 0.5] == 2) == sum(expectedchoice != 0.5))) {
## errortermneeded = 1
## }
## else {
## errortermneeded = 0
## }
## if (guessing != 1 & errortermneeded == 1) {
## typeerror = which(expectedchoice != 1/2)[1]
## if (choice[typeerror] == 0) {
## choice[typeerror] = 1
## messageerror = paste("### ERROR TERM: 1 A CHOICE ADDED TO TYPE OF TASKS ###",
## typeerror)
## }
## else {
## choice[typeerror] = numberOFtasksPerType[typeerror] -
## 1
## messageerror = paste("### ERROR TERM: 1 A CHOICE SUBTRACTED FROM TYPE OF TASKS ###",
## typeerror)
## }
## }
## expectedchoiceINVERTED = ifelse(expectedchoice ==
## 1/2, numberOFtasksPerType, expectedchoice)
## indexItemsInverted = which(expectedchoiceINVERTED ==
## 0)
## for (loopinversion in 1:length(indexItemsInverted)) {
## choice[indexItemsInverted[loopinversion]] = numberOFtasksPerType[indexItemsInverted[loopinversion]] -
## choice[indexItemsInverted[loopinversion]]
## expectedchoiceINVERTED[indexItemsInverted[loopinversion]] = numberOFtasksPerType[indexItemsInverted[loopinversion]]
## }
## numberOFmeasures = numberOFmeasures + 1
## }
## if (contrasttime[1] != "none") {
## time = dat$DECTIMES[dat$PARTICIPANT == partic[numbpartic]]
## typesTime = dat$TYPE[dat$PARTICIPANT == partic[numbpartic]]
## Ttime = contrasttime[typesTime]
## numberOFmeasures = numberOFmeasures + 1
## if (sd(time) == 0) {
## time = time + rnorm(length(time))
## messageerror = paste(messageerror, "### NO VARIANCE IN DECTIMES --> random noise N(0,1) added ###")
## }
## }
## if (contrastconfidence[1] != "none") {
## confidence = dat$CONFJUDGMENTS[dat$PARTICIPANT ==
## partic[numbpartic]]
## typesConfidence = dat$TYPE[dat$PARTICIPANT == partic[numbpartic]]
## Tconfidence = contrastconfidence[typesConfidence]
## numberOFmeasures = numberOFmeasures + 1
## if (sd(confidence) == 0) {
## confidence = confidence + rnorm(length(confidence))
## messageerror = paste(messageerror, "### NO VARIANCE IN CONFJUDGMENTS --> random noise N(0,1) added ###")
## }
## }
## if (expectedchoice[1] != "none") {
## if (guessing != 1) {
## Choice = function(epsil) {
## -sum(dbinom(choice, expectedchoiceINVERTED,
## prob = (((1 - epsil) * OnEpsilon) + FixedEpsilon),
## log = TRUE))
## }
## }
## else {
## Choice = function(epsil) {
## -sum(dbinom(choice, expectedchoiceINVERTED,
## prob = 1 - epsil, log = TRUE))
## }
## }
## }
## if (zerocontrasttime != 1) {
## Time = function(mu_Time = 8, sigma_Time, R_Time) {
## -sum(dnorm(time, mean = (mu_Time + (Ttime * abs(R_Time))),
## sd = sigma_Time, log = TRUE))
## }
## }
## else {
## Time = function(mu_Time, sigma_Time) {
## -sum(dnorm(time, mean = mu_Time, sd = sigma_Time,
## log = TRUE))
## }
## }
## if (zerocontrastconfidence != 1) {
## Confidence = function(mu_Conf, sigma_Conf, R_Conf) {
## -sum(dnorm(confidence, mean = (mu_Conf + (Tconfidence *
## abs(R_Conf))), sd = sigma_Conf, log = TRUE))
## }
## }
## else {
## Confidence = function(mu_Conf, sigma_Conf) {
## -sum(dnorm(confidence, mean = mu_Conf, sd = sigma_Conf,
## log = TRUE))
## }
## }
## start_epsilon = 0.5
## if (contrasttime[1] != "none") {
## start_mu_Time = mean(time)
## start_sigma_Time = sd(time)
## start_R_Time = sd(tapply(time, typesTime, mean))
## }
## if (contrastconfidence[1] != "none") {
## start_mu_Conf = mean(confidence)
## start_sigma_Conf = sd(confidence)
## start_R_Conf = sd(tapply(confidence, typesConfidence,
## mean))
## }
## if (expectedchoice[1] != "none") {
## if (guessing != 1) {
## fit1Func <- quote(mle())
## fit1Func$control <- controlParameterMLE
## fit1Func$start <- list(epsil = start_epsilon)
## fit1Func$method <- "BFGS"
## fit1Func$minuslog <- Choice
## fit1 = eval(fit1Func)
## }
## else {
## fit1Func <- quote(mle())
## fit1Func$control <- controlParameterMLE
## fit1Func$start <- list(epsil = start_epsilon)
## fit1Func$method <- "BFGS"
## fit1Func$minuslog <- Choice
## fit1Func$fixed = list(epsil = 0.5)
## fit1 = eval(fit1Func)
## }
## logliks[1] = logLik(fit1)
## }
## if (contrasttime[1] != "none") {
## if (zerocontrasttime != 1) {
## startTIME = list(mu_Time = start_mu_Time, sigma_Time = start_sigma_Time,
## R_Time = start_R_Time)
## }
## else {
## startTIME = list(mu_Time = start_mu_Time, sigma_Time = start_sigma_Time)
## }
## fit2Func <- quote(mle())
## fit2Func$control <- controlParameterMLE
## fit2Func$start <- startTIME
## fit2Func$method <- "BFGS"
## fit2Func$minuslog <- Time
## fit2 = eval(fit2Func)
## logliks[2] = logLik(fit2)
## }
## if (contrastconfidence[1] != "none") {
## if (zerocontrastconfidence != 1) {
## startCONFIDENCE = list(mu_Conf = start_mu_Conf,
## sigma_Conf = start_sigma_Conf, R_Conf = start_R_Conf)
## }
## else {
## startCONFIDENCE = list(mu_Conf = start_mu_Conf,
## sigma_Conf = start_sigma_Conf)
## }
## fit3Func <- quote(mle())
## fit3Func$control <- controlParameterMLE
## fit3Func$start <- startCONFIDENCE
## fit3Func$method <- "BFGS"
## fit3Func$minuslog <- Confidence
## fit3 = eval(fit3Func)
## logliks[3] = logLik(fit3)[1]
## }
## logliks = sum(logliks)
## BICs = (-2 * (logliks) + log(numberOFmeasures * numberOFtypes) *
## numberOFfreeParameters)[1]
## if (expectedchoice[1] != "none" & guessing != 1) {
## epsilon = coef(summary(fit1))
## epsilon = c(epsilon, coef(summary(fit1))[, 1]/coef(summary(fit1))[,
## 2])
## epsilon = c(epsilon, 2 * (1 - pnorm(abs(epsilon[3]))))
## epsilon = c(epsilon, epsilon[1] - epsilon[2] * 1.96,
## epsilon[1] + epsilon[2] * 1.96)
## if (contrasttime[1] == "none" & contrastconfidence[1] ==
## "none") {
## names(epsilon) = c("epsilon", "Std. Error epsilon",
## "z epsilon", "P>|z| epsilon", "2.5 % CI epsilon",
## "97.5 % CI epsilon")
## }
## }
## if (contrasttime[1] != "none") {
## outputSTRATtime = coef(summary(fit2))
## outputSTRATtime = cbind(outputSTRATtime, z = coef(summary(fit2))[,
## 1]/coef(summary(fit2))[, 2])
## outputSTRATtime = cbind(outputSTRATtime, `P>|z|` = 2 *
## (1 - pnorm(abs(outputSTRATtime[, 3]))))
## outputSTRATtime = cbind(outputSTRATtime, confint(fit2))
## stratOutput = outputSTRATtime
## }
## if (contrastconfidence[1] != "none") {
## outputSTRATconfidence = coef(summary(fit3))
## outputSTRATconfidence = cbind(outputSTRATconfidence,
## z = coef(summary(fit3))[, 1]/coef(summary(fit3))[,
## 2])
## outputSTRATconfidence = cbind(outputSTRATconfidence,
## `P>|z|` = 2 * (1 - pnorm(abs(outputSTRATconfidence[,
## 3]))))
## outputSTRATconfidence = cbind(outputSTRATconfidence,
## confint(fit3))
## stratOutput = rbind(stratOutput, outputSTRATconfidence)
## }
## stratOutput = rbind(epsilon, stratOutput)
## GSquared = function(numbConsistentObs = c(8, 9, 7, 7),
## epsilon = c(0.1, 0.1, 0.1, 0.1), totalNumberOfTasks = c(10,
## 10, 10, 10)) {
## numbInConsistentObs = totalNumberOfTasks - numbConsistentObs
## numbConsistentPred = totalNumberOfTasks * (1 - epsilon)
## numbInConsistentPred = totalNumberOfTasks * epsilon
## totalVectorObs = c(numbConsistentObs, numbInConsistentObs)
## totalVectorPred = c(numbConsistentPred, numbInConsistentPred)
## GSq = 2 * totalVectorObs * log(totalVectorObs/totalVectorPred)
## GSq = sum(GSq, na.rm = TRUE)
## degreesOfFreedom = length(numbConsistentObs) - 1
## pValue = 1 - pchisq(GSq, degreesOfFreedom)
## result = c(GSquared = GSq, `p(>= Gsquared)` = pValue)
## return(result)
## }
## if (expectedchoice[1] != "none") {
## epsilonGSquared = rep(epsilon[1], length(expectedchoice))
## epsilonGSquared = ifelse(expectedchoice == 0.5, 0.5,
## epsilonGSquared)
## consistentChoices = numberOFtasksPerType - abs(choice -
## expectedchoiceINVERTED)
## outputGSquared = GSquared(consistentChoices, epsilonGSquared,
## numberOFtasksPerType)
## }
## else {
## outputGSquared = numeric()
## }
## if (length(epsilon) > 0) {
## if (round(epsilon[1], 6) > 0.5) {
## messageerror = paste(messageerror, "### NOTE THAT EPSILON IS > .5 ###")
## }
## }
## namesStrat = colnames(stratOutput)
## memory = (rbind(memory, c(participant = partic[numbpartic],
## `strategy name` = stratname, `log-lik` = logliks,
## BIC = BICs, t(stratOutput), outputGSquared)))
## }
## epsilon = ifelse(length(epsilon) == 0, 0.5, epsilon)
## sub_header = numeric()
## numb = 0
## if (expectedchoice[1] != "none") {
## if (sum(expectedchoice == 0.5) != length(expectedchoice)) {
## sub_header = "choice"
## numb = numb + 1
## }
## }
## if (contrasttime[1] != "none") {
## if (sd(contrasttime) > 0) {
## sub_header = c(sub_header, "mu_Time", "sigma_Time",
## "R_Time")
## numb = numb + 1
## }
## else {
## sub_header = c(sub_header, "mu_Time", "sigma_Time")
## numb = numb + 1
## }
## }
## if (contrastconfidence[1] != "none") {
## if (sd(contrastconfidence) > 0) {
## sub_header = c(sub_header, "mu_Conf", "sigma_Conf",
## "R_Conf")
## numb = numb + 1
## }
## else {
## sub_header = c(sub_header, "mu_Conf", "sigma_Conf")
## numb = numb + 1
## }
## }
## labCol = paste(rep(sub_header, each = length(namesStrat)),
## rep(namesStrat, numb), sep = "_")
## if (numb > 0) {
## colnames(memory)[5:(length(labCol) + 4)] = labCol
## }
## memory_out_1 = memory[, 1:2]
## memory_out_2 = matrix(as.numeric((memory[, 3:ncol(memory)])),
## ncol = ncol(memory) - 2)
## memory_out = data.frame(memory_out_1, memory_out_2)
## colnames(memory_out) = colnames(memory)
## row.names(memory_out) = c()
## return(memory_out)
## }
## <bytecode: 0x000000000cc89958>
https://coherence.shinyapps.io/MMML/ or http://46.101.102.156:3838/sample-apps/MMML/

What have we learned?
Many references from the slides are listed here.
Bröder, A. (2005). Entscheiden mit der “adaptiven Werkzeugkiste”: Ein empirisches Forschungsprogramm. Pabst: Lengerich.
Gigerenzer, G., & Todd, P. M. (1999). Simple heuristics that make us smart. Oxford University Press.
Jeffreys, H. (1961). Theory of probability. University Press: Oxford.
Lee, M. (2015). Bayesian outcome-based strategy classification. Behavior Research Methods.
Lewandowsky, S., & Farrell, S. (2010). Computational modeling in cognition: Principles and practice. Sage: Los Angeles.
Schwarz, G. (1978). Estimating the dimension of a model. The annals of statistics, 6, 461–464.
{kind=link}